

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- yml파일
- 런타임에러
- 오산초밥
- aliexpress
- 가비지컬렉터
- 병목현상
- 형제초밥
- RAM
- 바이트코드
- 알리익스프레스
- 오산공영주차장
- 타코와사비
- java.lang.IllegalStateException: Ambiguous mapping found. Cannot map 'homeController' bean method
- 정적할당
- git오류
- Java
- 컴파일
- 육회초밥
- 동적할당
- 컴파일에러
- 바이너리코드
- 오산 회전초밥
- Please enter a commit message to explain why this merge is necessary
- yml유효성
- 기계어
- 1490원
- 오산주차장
- git pull
- 아이패드거치대
- 컴파일타임
- Today
- Total
개발 & 일상
컴파일(Compile)이란? 본문
글을 읽기 전에 이해를 돕기 위해 번역가 입장이 되어 생각을 해보자
1. 영문으로된 글을 한글로 번역하는 것은 컴파일이다.
2. 번역한 글을 책으로 엮는 것은 빌드이다.
3. 완성된 책을 고객들이 읽을 수 있도록 서점에 진열하는 것은 배포이다.
4. 1~2번 과정을 하나로 묶어 '빌드 한다'고 하기도 한다.
이걸 조금 더 프로그래밍적으로 바꾼다면?
1. 컴파일: 사용자가 작성한 코드를 컴퓨터가 이해할 수 있는 언어로 번역하는 일
2. 빌드: 컴파일된 코드를 실제 실행할 수 있는 상태로 만드는 일
3. 배포: 빌드가 완성된 실행 가능한 파일을 사용자가 접근할 수 있는 환경에 배치시키는 일
4. 혹은 컴파일을 포함해 war, jar 등의 실행 가능한 파일을 뽑아내기까지의 과정을 빌드한다고도 함.이렇게 간단히 보면 이해하기 쉬울 거라고 예상합니다.(참고만 하기)
조금 더 깊게 하나하나씩 봅시다.
1. 컴파일이란??
인간 친화적 언어(우리가 직접 쓴 코드, ' 고급 언어'라고도 함!)를
기계어(0과 1로 구성된 2진법, '저급 언어'라고도 함!) 바이너리코드로 (소스코드 분석 및 문법오류 분석도 해줌!)
번역해 주는 과정을 컴파일이라고 한다.
그리고 이것을 처리하는 프로그램을 컴파일러, 인터프리터 라고 한다.
(고급언어 와 저급언어로 나누는 기준
- 고급 프로그래밍 언어와 저급 프로그래밍 언어란 사람이 접근하기 쉬운가 어려운가의 차이를 두고 기준으로 하여 나뉘어 있다.
사람들에게 친숙한 언어로 이루어질수록 고급 언어에 속하고 컴퓨터가 이해하기 쉽고 가까운 언어일수록 저급언어로 분류된다.)
컴파일을 왜 해야 하는가??
기계(컴퓨터)는 우리가 쓴 코드들을 바로 이해할 수 없다.(컴퓨터는 0과 1로만 모든 명령을 이해하고 실행하기 때문!)
예를 들어보자!
만약 한국말을 쓰는 나 아랍어를 쓰는 외국인과 대화한다고 생각해 보면 각자 언어가 다른데 대화를 할 수 있을까?
서로 무슨 말을 하는지 모르고 의사소통이 안될 것이다.

번역이 필요하니깐 컴파일과정이 필요한 것!!
이렇게 소스코드를 기계어로 번역해 주는 프로그램에 사용되는 것이 크게 두 가지로 구분되어 보면 컴파일러 와 인터프린터이다
컴파일러 와 인터프린터 인터프린터는 일단 하는 역할은 같다.
위에 설명했듯이 사람이 이해할 수 있는 고급언어로 작성된 소스코드를
기계가 이해할 수 있는 기계어로 번역해서
프로그램을 실행하는 것이다.
이제 무슨 차이가 있는지 알아보자
컴파일러 (Compiler, 번역기)
컴파일러는 코딩을 마친 후 코드로 짜인 전체 소스들을
소프트웨어로 실행시키기 전 한 번에 기계어로 번역 역할을 해주는 놈이 컴파일러이다.
대표적으로 C, C++, C# 등의 언어가 있다. (Java는 조금 특이하게 인터프리터도 병행한다. 아래서 살펴보겠다. )
이런 컴파일 작업이 요구되는 언어들을 '컴파일러 언어'라고도 한다.
인터프리터(Interpreter, 실행기)
인터프리터(interpreter)란, 우리말로 '통역사'라는 뜻임.
우리가 컴퓨터에 명령을 내리면 한 줄씩 즉시 통역사가 컴퓨터 언어로 바꿔주는 거라고 생각하면 됨.
인터프리터는 컴파일러와는 다르게 한 줄 한 줄씩 번역을 진행한다. 번역과 실행이 동시에 이루어짐.
한 번에 번역해주는 컴파일러가 비해 번역 시간은 빠른 편.
하지만 번역을 할 때 실행 파일을 생성하지 않기 때문에 매번 똑같은 걸 실행하는데도 똑같은 번역을 또 해야 한다.
매번 번역을 거치기 때문에 인터프리터를 사용하는 언어들은 컴파일러를 사용하는 언어들에 비해 실행속도가 느린 편
인터프리터 작업이 요구되는 언어들은 인터프리터 언어 라고 한다.
대표적으로 자바스크립트, 파이썬, 루비 등의 언어가 있다.
JAVA는 컴파일과정이 어떻게 될까?
JAVA는
자바는 다른 컴파일 언어들이 작동하듯이 자바 컴파일러를 이용해 전체 코드를 한방에 번역한다.
이 과정은 컴파일러 언어와 같지만 자바 컴파일러는 코드를 바로 기계어로 번역해 주는 것이 아니라,
자바 가상 머신(JVM)이 실행시킬 수 있는 자바 바이트코드(class파일)로 번역한다.
(바이트코드 설명 참고) https://bengalseok91.tistory.com/17
보통 자바를 컴파일하고 나면. java 파일들이. class로 변환된 것을 확인할 수 있는데 클래스 파일은 바이트코드로 이루어져 있다.
자바 컴파일러가 하는 일. hellojava. java를 작성하면, javac (java compiler) 자바 컴파일러를 통해 hellojava.class로 변환.
.java --> javac(java compiler) -->. class (자바 바이트코드)
. class(자바 바이트코드) --> JVM(java interpreter) --> 100100001001 (기계어) --> 실행
여기서 봐야 할 것은. class 파일(java bytecode)에서 2진 코드(기계어)로 번역해 줄 때


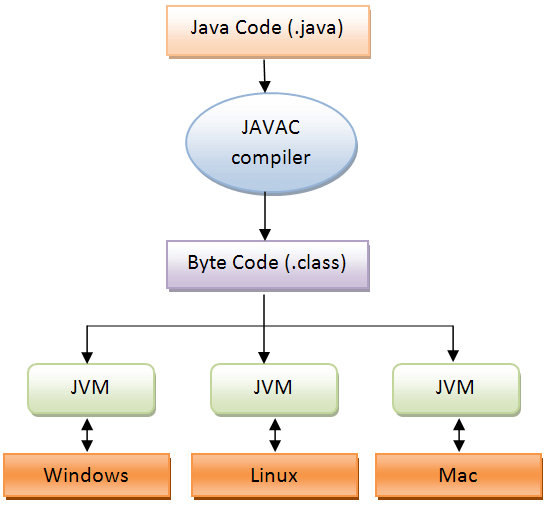
그림을 보면 이런 과정이다.
java는 jvm 덕분에 OS(리눅스, 윈도, 맥) 운영체제에 종속받지 않고 실행가능하다.
JVM은 JDK 안에 포함되어 있음!
(일반적으로 JDK를 설치하면 된다. JDK는 오라클 사이트에서 다운로드 가능하다. 자신의 운영체제에 맞는 JDK를 다운로드하면 된다.)
-JDK란?? (java로 소프트웨어를 개발할 수 있도록 여러 기능들을 제공하는 패키지(키트)
1. 개발자가 자바 소스코드(. java)를 작성합니다.
2. 자바 컴파일러가 자바 소스코드(. java) 파일을 읽어 바이트코드(. class) 코드로 컴파일합니다. 바이트코드(. class) 파일은
아직 컴퓨터가 읽을 수 없는 JVM(자바 가상 머신)이 읽을 수 있는 코드입니다. (java -> class)
3. 컴파일된 바이트코드(. class)를 JVM의 클래스로더(Class Loader)에게 전달합니다.
4. 클래스 로더는 동적로딩(Dynamic Loading)을 통해 필요한 클래스들을 로딩 및 링크하여
런타임 데이터 영역(Runtime Data Area), 즉 JVM의 메모리에 올립니다.
5. 실행엔진(Execution Engine)은 JVM 메모리에 올라온 바이트 코드들을 명령어 단위로 하나씩 가져와서 실행합니다.
이때 실행 엔진은 두 가지 방식으로 변경합니다.
이렇게 해도 잘 이해가 안 된다... 머리가 돌인 것인가? 며칠째 보고 있는데 왜 머리에 안 들어오냐...

이 그림을 보고 다시 이해해 보도록 하자..
1. Class Loader
JVM 내로 클래스 파일을 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈입니다. 런타임 시에 동적으로 클래스를 로드합니다.
2. Execution Engine
클래스 로더를 통해 JVM 내의 Runtime Data Area에 배치된 바이트 코드들을 명령어 단위로 읽어서 실행합니다.
최초 JVM이 나왔을 당시에는 인터프리터 방식이었기 때문에 속도가 느리다는 단점이 있었지만
JIT 컴파일러 방식을 통해 이 점을 보완하였습니다.
JIT는 바이트 코드를 어셈블러 같은 네이티브 코드로 바꿈으로써 실행이 빠르지만 역시 변환하는데 비용이 발생하였습니다.
이 같은 이유로 JVM은 모든 코드를 JIT 컴파일러 방식으로 실행하지 않고,
인터프리터 방식을 사용하다가 일정한 기준이 넘어가면 JIT 컴파일러 방식으로 실행합니다.(여기서 일정한 기준이 무엇인가?)
JVM 안에 자바 인터프리터 방식과 JIT 컴파일(JUST IN TIME compliation)
JIT 컴파일(JUST IN TIME compliation)
초기의 JVM 인터프리터방식의 단점을 보완하기 하기 위해 도입되었다.
JIT 가 컴파일 하는 대상은 소스 코드가 아니라 최적화를 한번 거친 바이트 코드다.
JIT 컴파일러는 전체 프로젝트 파일을 기계어로 번역하지 않고
함수 단위나 파일 단위로 바이트 코드를 기계어로 번역한다.
JVM 은 모든 코드를 JIT 방식으로 실행하지 않고 인터프리터방식을 사용하다가
자주 사용되는 코드만 골라서 캐싱(저장) 해놓는다.
이후엔 반복되고 자주 사용되는 코드는 캐싱된 코드를 재사용하여 인터프리터의 속도를 개선!
3. Garbage Collector
Garbage Collector(GC)는 힙 메모리 영역에 생성된 객체들 중에서 참조되지 않은 객체들을 탐색 후 제거하는 역할을 합니다. 이때, GC가 역할을 하는 시간은 언제인지 정확히 알 수 없습니다.
가비지컬렉터(Garbage Collector)
1. 메모리 할당
2. 사용 중인 메모리 인식
3. 사용하지 않는 메모리인식
'주소를 잃어버려서 사용할 수 없는 메모리', '정리되지 않은 메모리'. 즉, 쓰레기를 가비지라 칭한다.
(ex - 메모리를 가지고 있으나 수행이 완료되어 앞으로 사용하지 않고, 연결된 리모컨이 없는 객체)
가비지콜렉터는 이런 가비지들을 메모리에서 해제시켜 다른 용도로 사용할 수 있게 해주는 프로그램을 말한다.
(단 타이밍이나 점유 시간을 미리 예측하기 어렵다.)
C++와 같은 다른 언어에서는 사용하지 않을 객체의 메모리를 직접 해제해주어야 하지만
자바에서는 가비지컬렉터라는 알고리즘을 사용해 메모리를 관리한다.
GC의 구성
- Young Generation (새롭게 생성된 객체 할당, 대부분 여기에 생성됐다가 사라짐)
- Old Generation (Young Generation에서 살아남은 객체 할당(오랫동안 쓰일 객체라고 판단하면))
(GC 안에서도 구성과 동작과정이 있지만 정리를 못했다..)
4. Runtime Data Area
JVM의 메모리 영역으로 자바 애플리케이션을 실행할 때 사용되는 데이터들을 적재하는 영역입니다.
이 영역은 크게
Method Area,
Heap Area,
Stack Area,
PC Register,
Native Method Stack
로 나눌 수 있습니다.

1. Method area
모든 스레드가 공유하는 메모리 영역입니다.
메서드 영역은 클래스(class), 인터페이스, 메서드, 필드, Static 변수 등의 바이트 코드를 보관합니다.
2. Heap area
모든 스레드가 공유하며, new 키워드로 생성된 객체와 배열이 생성되는 영역입니다.
또한, 메서드 영역에 로드된 클래스만 생성이 가능하고 Garbage Collector가 참조되지 않는 메모리를 확인하고 제거하는 영역입니다.
모든 오브젝트(String, Integer, ArrayList 등등)
동적할당
메모리 동적할당이란, 프로그램을 실행하는 중 필요한 메모리 공간을 할당하는 것을 말한다.
사용이 끝나면 운영체제가 사용할 수 있도록 반납하고 다음 요구 시 재 할당을 받을 수 있다.
동적으로 할당된 메모리 공간은 프로그래머가 직접 해제하거나 가비지 컬렉터에 의해 해제된다.
java에서는 new 연산자를 할 때마다 힙 영역에 할당되며 gc의 대상이 된다.
동적 할당은 프로세스의 힙영역에서 할당하므로 프로세스가 종료되면 운영 체제에 메모리 리소스가 반납되므로 해제된다
int [] a;
a = new int [5];
new 연산자 등을 사용해 프로그램 도중 필요한 양만큼 할당하는 것 heap 메모리에 저장된다.
(프로그램 종료 시 garbage collector가 정리한다)
배열타입, 열거타입, 클래스(class), 인터페이스
1. 힙 영역은 객체와 배열이 생성되는 공간이고 참조타입(배열, 열거, 클래스, 인터페이스)들을 힙영역에 주소형식으로 저장한다.
2. 크기가 정해져 있지 않는 타입이다.
3. 메모리 할당 시 프로그램을 실행할 때 메모리를 빌려 동적으로 할당한다.
4. 참조하는 변수가 없다면 자동으로 힙 영역에서 제거된다.
3. Stack area

정적할당
메모리 정적할당은, 메모리의 크기가 하드 코딩되어 있기 때문에,
프로그램이 시작될 때 필요한 메모리의 크기를 예상해서 미리 할당(확보) 한다는 특징을 갖는다.
정적할당된 메모리의 경우 프로그램을 실행하는 도중에는 해제되지 않고 있다가, 프로그램 종료 시 운영체제가 회수해 간다.
메모리를 미리 stack memory에 확보해 둔다.
int [] a = new int [10];
함수종료될때까지 안 쓰는 메모리가 낭비된다.
- 함수 호출이 끝나면 사라진다.
메서드 호출 시마다 각각의 스택 프레임(그 메서드만을 위한 공간)이 생성합니다.
그리고 메서드 안에서 사용되는 값들을 저장하고
호출된 메서드의 매개변수, 지역변수, 리턴 값 및 연산 시 일어나는 값들을 임시로 저장합니다.
마지막으로, 메서드 수행이 끝나면 프레임별로 삭제합니다.
정수타입 : byte/char/short/int
실수타입 : float / double
논리타입: boolean
1. 스택 영역은 변숫값을 저장하게 되는데 기본타입인 정수형 변수와 실수형 변수와 논리형 변수를 실제값으로 저장한다.
2. 크기가 정해져 있는 타입이다.
3. 메모리 할당 시 컴파일할 때 이미 계산이 이루어진다.
public class Main {
public static void main(String[] args) {
int port = 4000;
String host = "localhost";
}
}

4. PC Register
스레드가 시작될 때 생성되며, 생성될 때마다 생성되는 공간으로 쓰레드마다 하나씩 존재합니다.
쓰레드가 어떤 부분을 무슨 명령으로 실행해야 할 지에 대한 기록을 하는 부분으로 현재 수행 중인 JVM 명령의 주소를 갖습니다.
명령어 주소 저장공간
5. Native method stack
자바 외 언어로 작성된 네이티브 코드를 위한 메모리 영역입니다.
그럼 자바 스크립트에선 어떨까?
자바 스크립트는 인터프리터 언어인데 컴파일과정을 거친다는 게 말이 될까? 실시간 번역인데?
js에서도 인터프리터방식의 단점을 보완하기 위해 Chrome의 V8 엔진에서 JIT컴파일 방식을 해서 쓴다.
V8 엔진

Google에서 만든 JavaScript 컴파일러로 C++언어를 기반으로 만들어졌습니다.
때문에 독립적으로 실행이 가능하며, 다른 웹 브라우저 없이 JavaScript, Node.js 코드를 컴파일할 수 있습니다.
자바스크립트 엔진 내부에서는 컴파일과정이 있다
어느 부분에서 컴파일 과정이 있다는 걸까...
자바스크립트 엔진이 코드를 넘겨받는 시점
랜더링 엔진은 HTML을 읽다가 <script>를 만나면 잠시 작업을 일시중단 한다.
이때 읽어 들인 Js코드가 자바스크립트 엔진에서 해석, 실행될 때까지 멈추는 것이다.
코드를 넘겨받고 해석하는 과정은 다음과 같다.
해석 == 컴파일레이션 (이 부분이 컴파일 과정이라고 추측)

엔진은 text형식인 코드를 실행하기 전 컴파일 과정을 거친다.
컴파일은 총 3개의 단계로 이루어져 있다.
- 코드를 의미 있는 조각으로 나누는 렉싱/토크나이징 (이때 스코프가 결정된다 - 렉시컬스코프라 부르는 이유)
- 코드를 트리구조로 나타내는 AST로 만드는 파싱,
- VM이 실행할 수 있도록 트리를 가지고 바이트코드로 변환하는 컴파일 과정으로 이루어져 있다.
컴파일레이션을 통해 JS코드가 실행되기 직전에 컴파일된다는 것을 알 수 있었다.
실행되는 그림을 보자
자바스크립트 엔진이 코드를 넘겨받는 시점에서 위 그림처럼 작업이 끝나면 결과를 실행한다.

Parser 부분이 해석 == 컴파일레이션(위 그림 참조)
JIT Compiler는 이 두 개를 합친 것으로 실행시점에서 인터프리터 방식으로 바이트 코드를 생성합니다.
그 후 V8 Engine은 바이트 코드를 기계어 코드로 만들고, 그 코드를 캐싱하여,
같은 함수가 여러 번 불릴 때 매번 기계어 코드를 생성하는 것을 방지합니다.
(인터프리터 방식은 한 줄 읽고 실행하는 방식으로, 동일한 동작을 하는 함수가 여러 번 나오더라도 이를 컴파일하는 과정을 거치게 됩니다. 따라서 이는 매우 비효율적이며, JIT Compiler는 이를 방지하여 위와 같은 동작으로 실행되게 됩니다.)
그렇다고 무조건 적으로 JIT 가 좋은 것은 아니다.
JIT를 사용하는 이유가 반복되는 빈도가 높아질 때 만들어 놓은 기계어를 재사용할 수 있어서라고 했는데 만약 자주 반복되는 코드가 거의 없다면 기계어(native code라고 표현)를 수행하는 시간보다 만드는 시간이 더 걸릴 수 있다.
반복이 많이 되면 유동적으로 JIT, 아니면 interpreter로 수행!
이 설명들이 맞는 건가..ㅎㅎ
'💻 개발공부 > 😈 개발지식' 카테고리의 다른 글
| RAM 이란?? && S RAM vs D RAM (0) | 2023.01.16 |
|---|---|
| 빌드(Build)란? (1) | 2023.01.14 |
| Java 의 정적할당(static) / 동적할당(dynamic) (0) | 2023.01.14 |
| 런타임(Run Time) 이란? & 컴파일타임 (1) | 2023.01.14 |
| 바이트 코드와 바이너리코드 & 기계어 (0) | 2023.01.14 |

